FreeBSD 14의 TCP 관련 업데이트
제가 집중하고 있는 FreeBSD 프로젝트의 영역, 즉 TCP 프로토콜 구현에 대해 마지막으로 보고한 지 약 3년 반이 지났습니다. 잘 모르시는 분들을 위해 설명하자면, FreeBSD에는 하나의 TCP 스택만 있는 것이 아니라 여러 개의 스택이 있으며, 주로 RACK과 베이스 스택에서 개발이 이루어지고 있습니다. 현재 기본으로 사용되는 스택(베이스 스택)은 오랫동안 발전되어 BSD4.4에서 파생된 스택입니다. 또한, 2018년부터 완전히 리팩터링된 스택("RACK 스택" - 최근 ACKnowledgement 메커니즘의 이름을 딴 것)이 기본 스택에 부족한 많은 고급 기능을 제공합니다. 예를 들어, RACK 스택은 높은 세분성 페이싱 기능을 제공합니다. 즉, 스택은 패킷 전송 시간을 조정하고 네트워크 리소스 소비를 균등하게 조정할 수 있습니다. 반대로 애플리케이션에서 갑자기 많은 양의 데이터를 전송해야 하는 경우, 이 데이터가 회선 속도(CPU와 내부 버스가 병목 현상이 없는 경우 인터페이스의 속도)에 가까운 속도로 대량으로 전송되는 경우가 있습니다. 특히 마지막 애플리케이션 IO에서 수십 밀리초 정도의 짧은 애플리케이션 일시 정지가 있을 때 가장 많이 발생합니다. (RACK 스택에 대한 자세한 내용은 이 글의 범위를 벗어나며, 함께 첨부된 Michael Tuexen과 Randall Stewart의 글에서 확인할 수 있습니다).
여기서는 기본 스택에 추가된 몇 가지 새로운 기능 중 많은 기능이 기본적으로 활성화되어 있고 일부는 특별히 활성화해야 할 수도 있는 기능에 대해 중점적으로 설명하고자 합니다. 각 기능에 대해 네트워킹 환경을 개선하는 데 도움이 될 수 있는 세부 사항을 설명하겠습니다.
전체적으로, FreeBSD 13.0이 출시된 이후 모든 전송 프로토콜이 전통적으로 있는 sys/netinet 디렉토리에 약 1033개의 커밋이 있었습니다. 여기에서는 기능이 개선된 베이스 스택의 일부 변경 사항에 대한 개요를 제공합니다:
Proportional Rate Reduction (비례 전송율 감소)
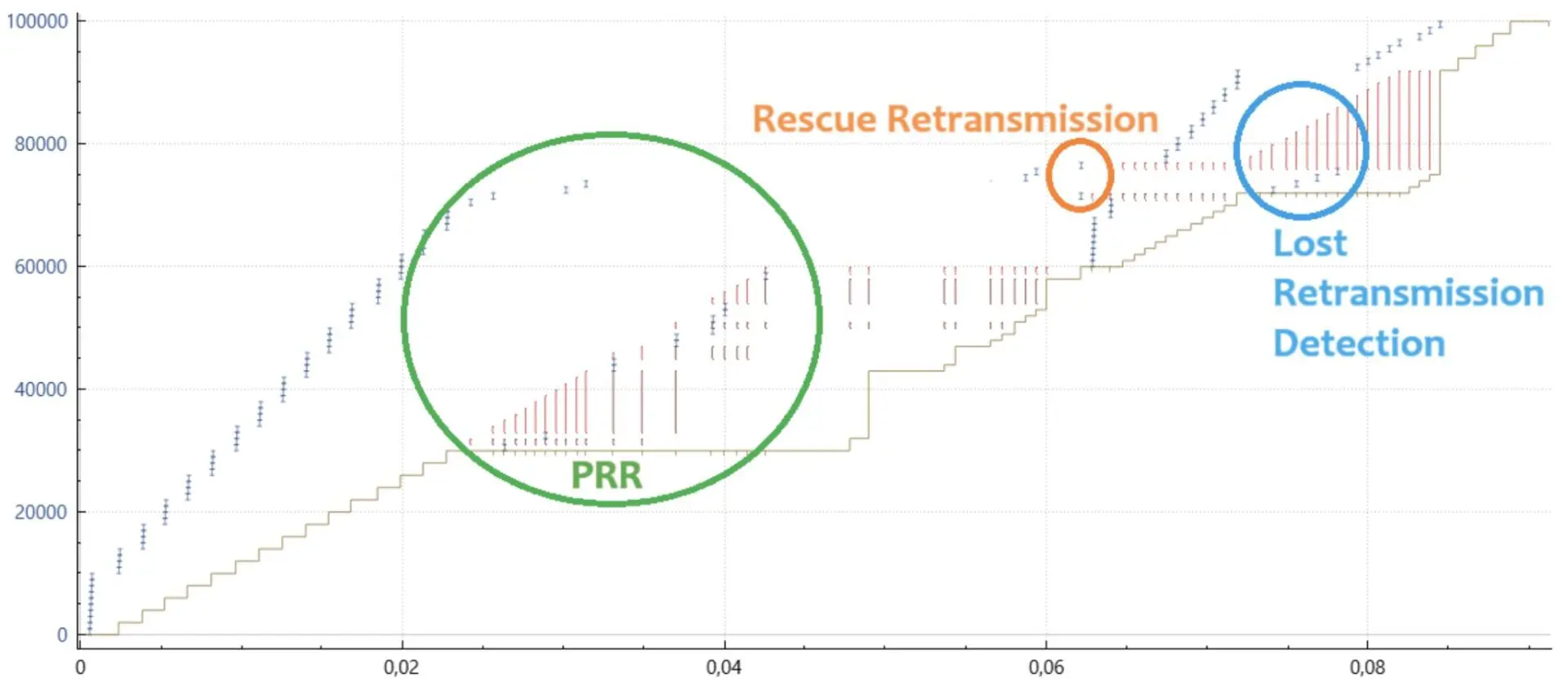
기본 스택에 도입된 첫 번째 기능은 PRR - 비례 전송률 감소(RFC6937)입니다. PRR을 높은 수준에서 이해하기 위해 먼저 손실 복구 중 SACK 동작이 어떻게 작동하는지 이해해 보겠습니다. 표준 SACK 손실 복구의 한 가지 문제는 단일 패킷 손실 후 손실 복구에 들어갈 때 혼잡 창이 조정되지만(예: NewReno의 경우 혼잡 시작 시 값의 50%, Cubic의 경우 70%로), 아직 전송 중인 패킷 수를 추정하여 처음에는 ACK가 전반(NewReno) 또는 창 초기 30% 동안 반환되는 동안 패킷 전송을 허용하지 않는다는 것입니다. 이 한도에 도달하면 들어오는 모든 ACK는 새 패킷을 유도하지만 네트워크의 혼잡 지점을 압도하는 효과적인 속도로 발생할 수 있습니다. 초기의 조용한 기간은 대기열을 없애고 이후 이상적인 속도보다 빠른 전송을 허용하는 역할을 할 수 있습니다. 이러한 동작은 종종 후속 손실(재전송된 패킷의 손실까지 포함할 수 있습니다. 자세한 내용은 나중에 설명합니다.)로 이어집니다.
효과적인 전송 속도를 신속하게 조정하고 데이터 패킷의 손실이 여러 번 발생하거나 ACK 패킷이 손실되는 경우에도 보다 적절하게 대처하기 위해 PRR은 새로 들어오는 모든 ACK에 대해 전송해야 하는 데이터 양을 계산하고 그 시점에 적절한 만큼의 풀사이즈 패킷을 전송합니다. 혼잡 구간이 절반으로 줄어들고 손실이 한 번만 발생하는 NewReno의 간단한 예에서, 이렇게 하면 두 개의 ACK가 반환될 때마다 하나의 새 패킷이 전송됩니다. 따라서 전송 속도가 이전의 절반 수준으로 즉시 조정되어 혼잡한 디바이스에 과부하가 걸리지 않습니다. 여러 번의 데이터 손실 또는 버려진 ACK가 있는 경우, PRR은 최종적으로 ACK가 수신될 때 한 개 이상의 패킷을 주입하여 놓친 전송 기회를 잘 활용할 수 있습니다. 전반적으로 이 동작은 손실 복구가 발생하는 창(RTT)의 끝에서 유효 혼잡 창이 예상 혼잡 창에 최대한 가깝게 유지되도록 하며, 여러 패킷 손실 또는 ACK 손실과 같은 문제가 있는 시나리오에서도 전송 기회를 놓치지 않도록 보장합니다.
몇 가지 그래프를 통해 이 세부 사항을 더 잘 설명할 수 있기를 바랍니다. 아래에는 와이어샤크 또는 tcptrace와 관련 xplot의 조합을 통해 얻을 수 있는 시간 순서 그래프가 있습니다. 작은 파란색 세로 막대는 왼쪽 축에서와 같이 데이터 시퀀스를 포함하는 특정 패킷이 전송된 시점을 나타냅니다. 아래의 녹색 가로줄은 수신자가 연속적으로 수신한 데이터를 나타냅니다. 빨간색 세로선은 수신기에 도달한 데이터의 불연속적인 범위를 나타냅니다.
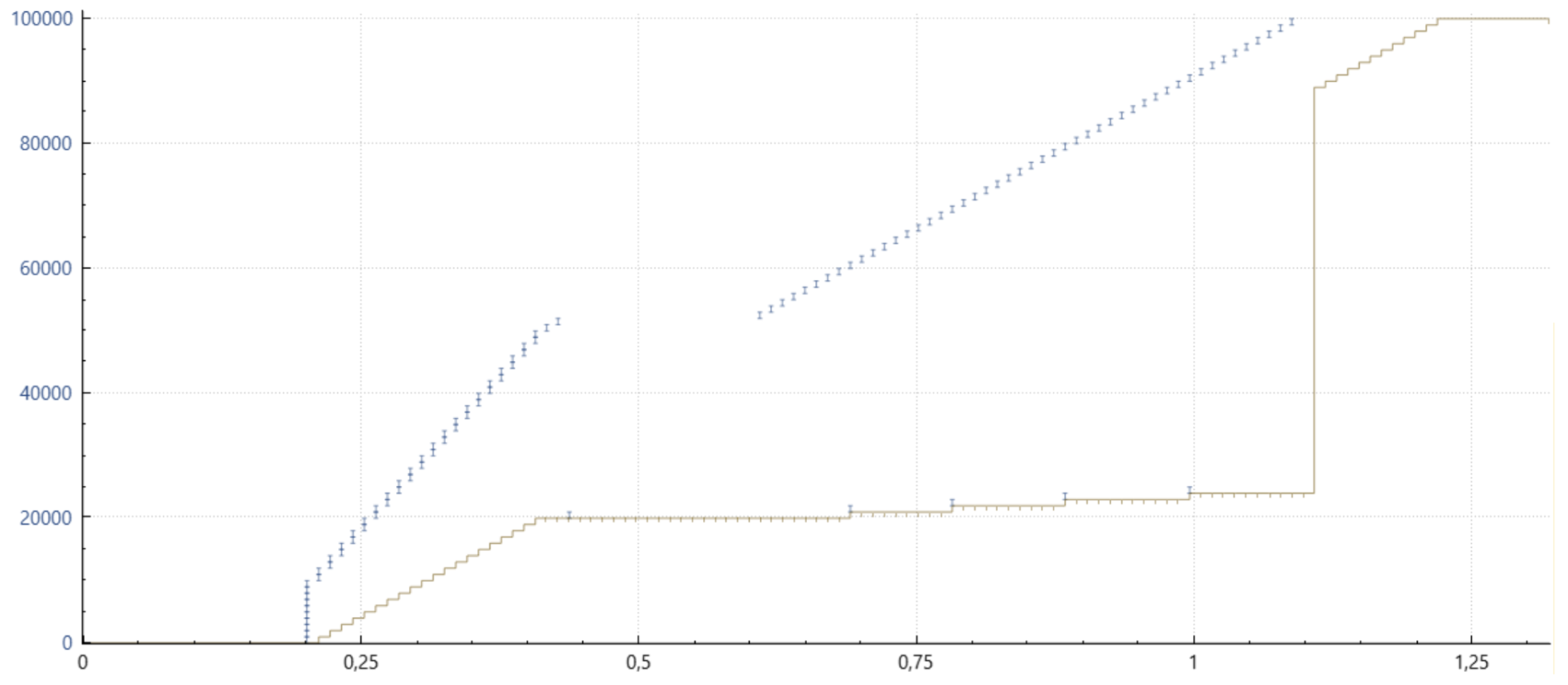
Cubic Without SACK or PRR, Classic NewReno Loss Recovery
하나의 창(또는 왕복 시간) 내에 하나의 데이터 패킷만 복구할 수 있으며, 가로로 길게 늘어진 녹색 선은 수신 애플리케이션이 추가 데이터를 처리하기까지 발생하는 지연 시간을 나타냅니다.
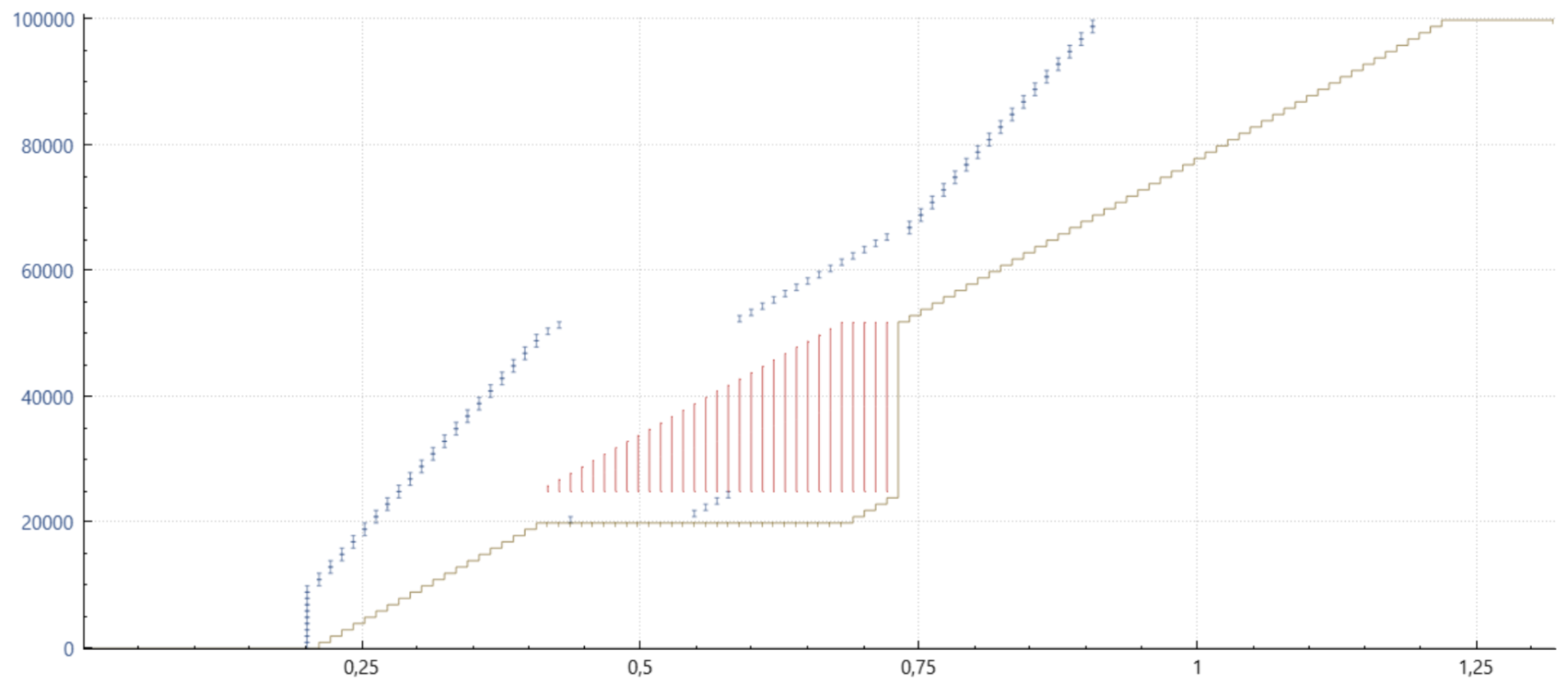
Cubic with SACK, but no PRR
이 예시에서 볼 수 있듯이, SACK은 손실된 모든 패킷을 (일반적으로) 하나의 RTT 내에 재전송할 수 있기 때문에 상황을 극적으로 개선합니다. 그러나 나중에 각 ACK에서 전송이 일시 중지되었다가 다시 시작된다는 점에 유의하세요. 이 동작은 데이터를 유효 속도로 전송하기 때문에 일부 패킷이 네트워크에서 삭제될 수 있습니다. 이로 인해 하나 이상의 재전송이 너무 빨리 도착하여 네트워크에서 재전송을 삭제하는 경우가 종종 있습니다. 이 경우 유일한 방법은 재전송 시간 초과(RTO)를 기다리는 것입니다.
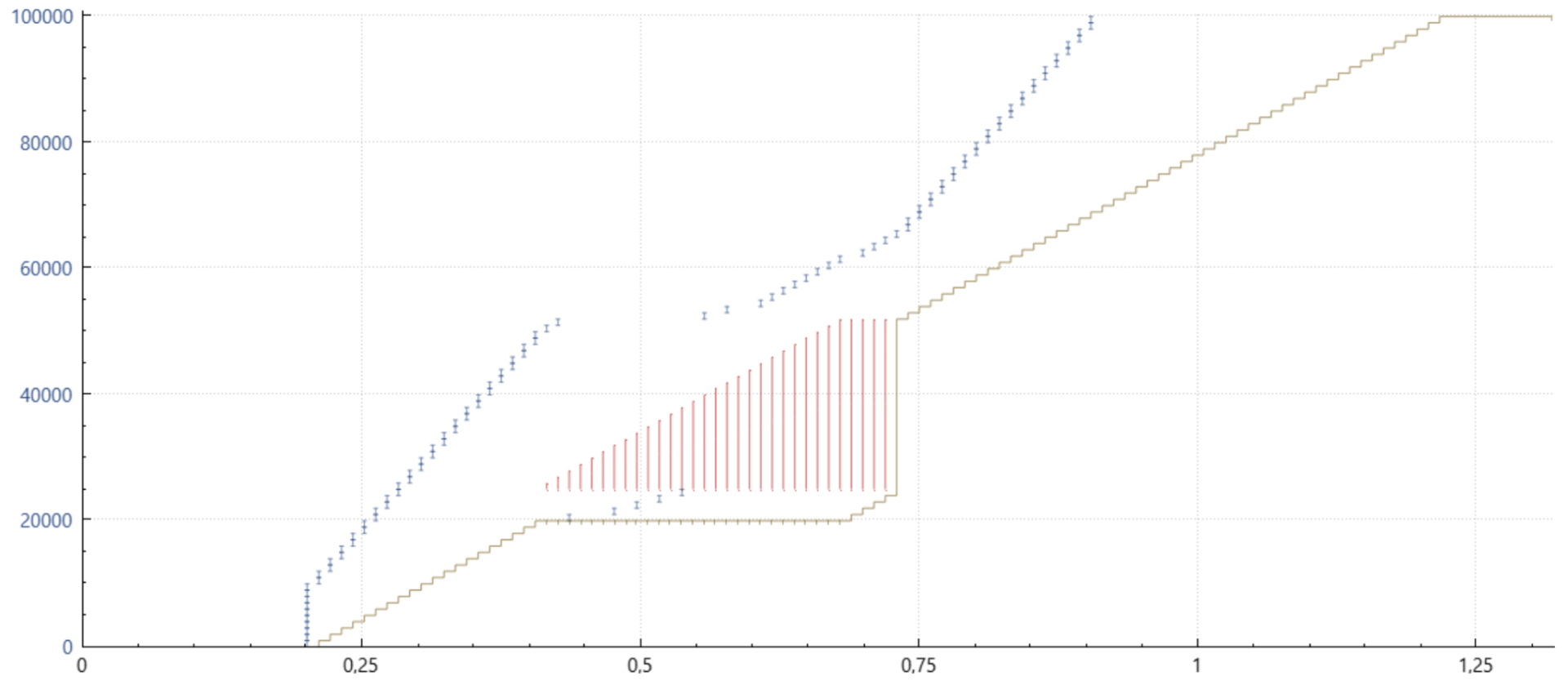
Cubic with SACK (6675) and PRR
여기에 표시된 PRR의 개선 사항은 미묘합니다. 이전에는 절반의 시간 동안 데이터가 전송되지 않고 후반부에는 너무 높은 전송률로 전송되었다면, PRR은 새로운 전송률에 도달할 때까지 거의 매번 수신되는 ACK에 패킷을 주입한 다음, 이후 들어오는 거의 모든 ACK에 패킷을 주입합니다. 이는 재전송의 유효 전송률을 낮추고 네트워크에서 재전송이 버려질 가능성을 낮추는 역할을 합니다. 결과적으로 RTO가 줄어들고 지연 시간이 개선됩니다.
여기에 표시된 그래프는 완전히 정확하지는 않지만 수신된 ACK를 적절히 디더링하여 전송하는 PRR의 패킷 전송 측면을 전달하려고 시도한 것으로, 이 경우 네트워크에서 버려졌을 수 있는 패킷을 포함하여 평균적으로 모든 ACK당 0.7개의 패킷이 전송됩니다.
이 분야의 마지막 업데이트는 이제 손실 복구에 추가적인 손실이 발생하지 않는 한 PRR이 자동으로 덜 보수적인 모드로 전환된다는 것입니다. 이는 혼잡 회피 단계에서 정상 작동할 때와 유사하게 손실 복구 중 전송 속도를 효과적으로 개선합니다. PRR은 (당연히) SACK과 함께 사용할 때 가장 잘 작동하지만, SACK이 아닌 중복 ACK만 사용할 수 있는 경우에도 마찬가지입니다. ECN 피드백만 있어도 PRR은 전송 타이밍을 개선합니다.
SACK Handling
최근 몇 년 동안 RFC6675에 명시된 SACK 손실 복구에 대한 기본 스택의 준수 여부가 개선되었습니다. 그러나 네트워크에 아직 남아 있는 데이터의 양에 대한 추정의 일부가 개선되었지만, RFC6675의 다른 측면이 누락되었습니다.
이제 이 분야의 개선 사항에는 RACK 스택에서 구현되는 꼬리 손실 프로브의 선구자인 구조 재전송의 사용이 포함됩니다. 즉, 이전 패킷 손실에 더해 전송의 마지막 몇 개의 패킷이 손실되면 스택이 문제를 감지하고 최종 패킷을 재전송하여 적시에 손실 복구를 수행합니다.
또한 스택은 들어오는 SACK 블록을 처리할 때 추가 계정을 구현하여 특정 패킷이 수신되었거나 삭제되었을 가능성이 매우 높은 패킷이 네트워크를 떠나야 하는지 여부를 더 잘 추적합니다.
마지막으로 개선된 기능은 재전송도 네트워크에서 삭제되었는지 여부를 추적하는 것이었지만, 시간 도메인을 사용하는 RACK과 달리 기본 스택은 시퀀스 도메인을 살펴봅니다. 이러한 손실된 재전송 감지는 RFC 시리즈에 명시되어 있지는 않지만, TCP 스택을 사용하는 모든 요청-응답(예: RPC) 프로토콜의 흐름 완료 시간/IO 서비스 응답 시간을 줄이는 데 매우 유용한 추가 기능입니다. 손실된 재전송을 추적하고 복구하는 기능은 아직 기본적으로 제공되지 않습니다. FreeBSD 14에서는 net.inet.tcp.do_lrd로 활성화할 수 있지만, FreeBSD 15에서는 net.inet.tcp.sack.lrd로 이동하여 기본적으로 활성화할 수 있습니다.
전반적으로, 이러한 변경 사항은 IP 네트워크의 혼잡과 관련하여 자주 발생하는 병리적 문제에서 기본 스택의 복원력을 향상시킵니다.
마지막으로, 기본 스택(및 RACK 스택)은 가짜 중복 데이터 패킷을 수신할 때 DSACK(RFC2883) 응답을 생성합니다. 이러한 DSACK 정보를 수신해도 스택 동작에는 영향을 미치지 않지만, 이 정보를 원격 발신자에게 제공하면 해당 발신자가 특정 네트워크 경로 동작에 더 잘 적응할 수 있습니다(예: Linux는 경로 왕복 시간(RTT)의 급격한 증가로 인해 듀프스레시를 높이거나 허위 재전송을 감지할 수 있음).
Logging and Debugging
수십 년 동안 베이스 스택은 라이브 시스템에서 디버깅할 수 있는 여러 가지 메커니즘을 축적해 왔습니다. 가장 잘 알려지지 않은 도구 중 하나인 trpt와 그 지원은 FreeBSD 14에서 제거되었습니다. 하지만 여전히 수많은 다른 옵션이 존재합니다(dtrace, siftr, bblog, ...).
블랙박스 로깅은 RACK 스택과 함께 도입되었고 점점 더 많은 기본 스택을 포함하도록 확장되었습니다. 실행 중인 시스템에서 내부 상태 변화를 추출하고 패킷 추적 자체와 함께 코어 덤프에서 추출하는 도구가 준비되고 있습니다. (https://github.com/Netflix/tcplog_dumper 및 https://github.com/Netflix/read_bbrlog 참조)
Cubic
이전 글에서 설명한 것처럼, TCP 큐빅은 거의 모든 곳에서 사용되는 사실상 표준 혼잡 제어 알고리즘입니다. 최근에는 어떤 TCP 스택을 사용하든 상관없이 FreeBSD의 기본값으로 큐빅이 지정되기도 했습니다.
여기서 주목할 만한 확장 기능 중 하나는 HyStart++의 추가입니다. TCP 세션이 시작되면 혼잡 제어 메커니즘은 슬로우 스타트라고 불리는 단계에서 대역폭을 빠르게 증가시킵니다. 일반적으로 슬로우 스타트 단계는 혼잡 패킷 손실의 첫 징후 또는 명시적 혼잡 알림(ECN) 피드백이 수신되면 종료됩니다. 큐빅 모듈의 일부로 구현되어 항상 활성화되어 있는 HyStart++를 사용하면 RTT가 모니터링됩니다. 네트워크 대기열이 형성되기 시작하여 RTT가 상승하기 시작하면 덜 공격적인 단계(보수적인 슬로우 스타트)로 진입하고 타이밍 기반 신호는 안정적으로 확보하기 어렵기로 악명이 높기 때문에 RTT는 계속 모니터링됩니다. 이 보수적 슬로우 스타트 단계에서 RTT가 다시 감소하면 일반 슬로우 스타트가 재개됩니다. 그렇지 않은 경우, CSS의 덜 공격적인 전송 속도는 소위 오버슈트(불가피한 손실로 인해 복구해야 하는 데이터의 양)를 제한합니다.
Accurate Explicit Congestion Notification
앞서 언급했듯이 ECN은 혼잡 이벤트를 나타내는 유일한 신호로서 패킷 손실을 방지하는 메커니즘입니다. 지난 10년 동안 인터넷 엔지니어링 태스크포스(IETF)에서는 이 시그널링을 개선하기 위해 많은 노력을 기울여 왔습니다. 원래 ECN은 패킷 손실과 "동일한" 신호로 간주되었지만, 의미가 다른 더 빈번한 신호가 넓은 대역폭에서 얕은(빠른) 대기열을 유지하는 데 더 효과적이라는 것이 밝혀졌습니다. 전체 아키텍처의 이름은 저지연, 저손실, 확장성(L4S)입니다. 현재 FreeBSD의 모든 부분이 제대로 된 "TCP Prague" 구현을 구현할 준비가 되어 있지는 않지만, DCTCP 혼잡 제어 모듈과 여기서는 정확도 높은 ECN(AccECN)과 같은 많은 개별 기능이 이제 FreeBSD 14에서 스택의 일부가 되었습니다.
기존 ECN에서는 RTT당 하나의 혼잡 경험 마크만 시그널링할 수 있었습니다. 따라서 혼잡 제어 모듈에 의한 집중적인 관리가 필요했습니다. 실제로 CE 마크는 RFC3168 모드에서 작동하는 동안 TCP 대역폭을 조정할 때 패킷 손실 표시와 동일한 것으로 간주됩니다. 이와는 대조적으로, AccECN을 사용하면 수신자가 임의의 수의 명시적 혼잡 표시를 데이터 발신자에게 다시 보낼 수 있습니다. 이를 통해 네트워크에서 보다 변조되고 세분화된 신호를 추출할 수 있습니다. 이는 중간 스위치에 의해 훨씬 더 공격적인 마킹 임계값이 수정된 DCTCP를 사용해야 하는 환경에서 특히 유용합니다. 또한 TCP Prague라고도 알려진 저지연, 저손실, 확장성(L4S) 아키텍처의 핵심 요소 중 하나이기도 합니다.
Authentication and Security
최근 RACK 스택은 TCP 패킷의 MD5 인증을 완벽하게 처리할 수 있는 기능을 갖추게 되었습니다. 이는 RACK 스택에서 BGP를 사용할 수 있도록 개선된 기능으로, RACK 스택이 모든 일반적인 상황에서 완전한 기능을 갖추고 사용할 수 있도록 하는 또 다른 단계입니다.
오랫동안 RFC7323(RFC1323)의 두 가지 기능인 윈도우 스케일링과 타임스탬프 옵션 사이에는 긴밀한 결합이 있었습니다. 이제 이 공간에서 두 기능 중 하나를 독립적으로 활성화할 수 있도록 허용하는 한편, 기본값은 여전히 둘 다 활성화할 수 있도록 허용합니다. 이제 net.inet.tcp.rfc1323을 켜기(1) 또는 끄기(0)뿐만 아니라 2(창 크기만) 및 3(타임스탬프만)으로 설정하여 이 기능을 구현할 수 있습니다. 또한 RFC7323에 따라 이제 모든 상황에서 TCP 타임스탬프를 적절히 사용하도록 요구함으로써 TCP 세션을 더욱 안전하게 보호할 수 있습니다. 이는 net.inet.tcp.tolerate_missing_ts를 0으로 설정하면 됩니다.
What’s Next?
TCP 기능의 다양한 측면에 대한 개선이 반환 감소 단계에 접어들었지만, 아직 몇 가지 추가 개선 사항이 논의 중입니다.
예를 들어, RFC2018(선택적 승인)의 부칙에 따라 이전과 달리 재전송 시간 초과(RTO) 동안 정보를 보관할 수 있게 되었습니다. 원래 표준 당시의 주된 동기는 수신자의 '리니게이팅'을 허용하는 것이었습니다. 명시적으로 승인하지 않는 한, 메모리 압박 등의 이유로 후속 데이터를 버릴 수 있었습니다. 실제로 이러한 리니게이팅은 거의 발생하지 않지만, SACK 손실 복구 단계에서 재전송 시간 초과가 발생하는 경우는 꽤 자주 발생합니다. 이 정보를 유지하면 RTO 이후에도 보다 효율적으로 재전송할 수 있습니다. 문제는 기본 스택이 재전송 시간 초과 후 발생해야 하는 다른 측면(예: 매우 작은 혼잡 창에서 느리게 시작)과 암묵적으로 긴밀하게 연결되어 있다는 것입니다. 또한 더미넷 경로 에뮬레이터에 몇 가지 추가 기능을 추가하여 손실을 보다 제어 가능한 방식으로 모델링하는 등 RTO 이후 이러한 변경의 영향을 평가해야 합니다.
리차드 셰페네거는 2020년 4월부터 FreeBSD 커미터로 활동하고 있으며, 주로 느린 경로(손실 복구, 혼잡 제어 처리)에 중점을 두고 TCP 스택의 기능을 개선하는 데 관심을 갖고 있으며, IETF와 함께 정확한 ECN과 같은 개선 사항을 적극적으로 개발하고 있습니다.